Case Study - GEO prompt tracker
🚀 Case Study: Accelerating Generative Engine Optimization (GEO) with Automated LLM Auditing
Client: A leading digital strategy firm focused on B2B content authority.
1. The Challenge: Auditing LLM Grounding and Consistency
As Generative Engine Optimization (GEO) became a critical component of their digital strategy, the digital strategy firm recognized a fundamental gap: the lack of a scalable, objective method for auditing the performance and source grounding of major Large Language Models (LLMs).
Their goal was to ensure their clients' key information and brand message, specifically mentioning a proprietary offering, "Innovativecompass," was accurately and consistently reflected in AI-generated answers.
The Manual Bottleneck:
- Labor-Intensive Testing: To compare answers, a researcher had to manually execute the same complex query across four distinct platforms: Perplexity, Claude Sonnet, Gemini, and ChatGPT.
- Time-Consuming Data Extraction: Following the search, the researcher would spend hours copying the raw text, extracting cited URLs, categorizing each source (e.g., news site, forum, company blog), and compiling a unique list of all other companies mentioned.
- Inconsistent Data Quality: This manual process was slow, non-standardized, and highly susceptible to human error and subjective categorization, making accurate, side-by-side comparison of LLM performance virtually impossible. The inability to track keyword mentions and source quality at scale severely hampered their ability to implement a data-driven GEO strategy.
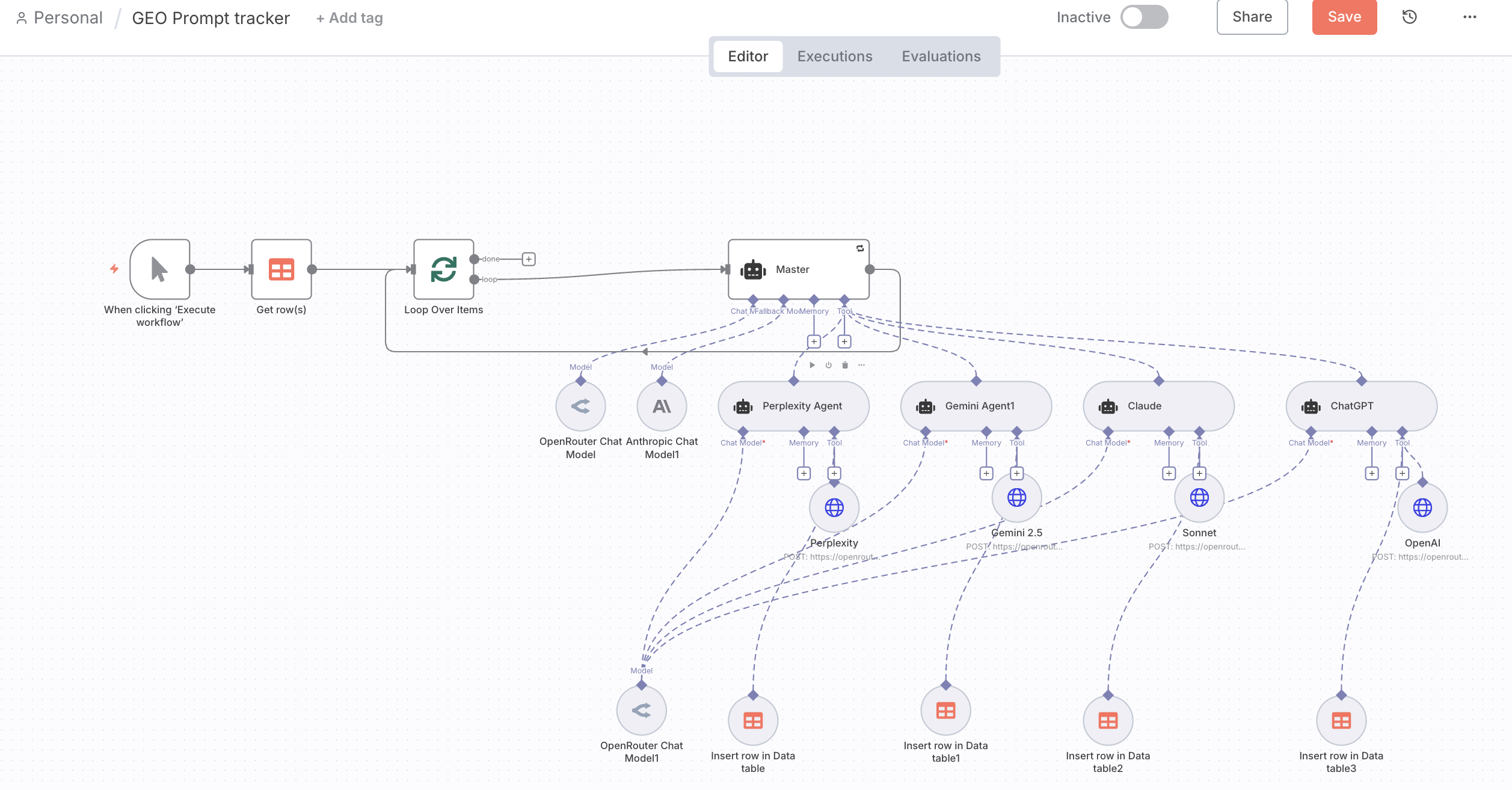
2. The Solution: The GEO Prompt Tracker Workflow
The firm partnered to implement a sophisticated, automated GEO Prompt Tracker Workflow, built on a powerful Master/Sub-Agent architecture. This solution was designed to perform parallel, standardized auditing of LLM responses, eliminating manual effort and guaranteeing data consistency.
The workflow operates by taking a single search query and delegating the execution, extraction, and initial categorization to four specialized, parallel AI sub-agents.
Key Steps of the Automated Solution
The workflow transformed a sequential, error-prone manual task into a rapid, parallelized, and self-auditing process.
- The Query Trigger and Data Loop:
- Action: The system initiates a test either manually or on a schedule, retrieving a list of target search queries from a central data source.
- Value: Enables batch testing and continuous monitoring of critical business queries, moving beyond single-shot manual checks.
- The Master Orchestrator Agent:
- Action: A dedicated Master Agent receives the query and simultaneously dispatches it to four distinct sub-agents.
- Value: Leverages parallel processing to dramatically cut down the total execution time compared to a manual, sequential approach.
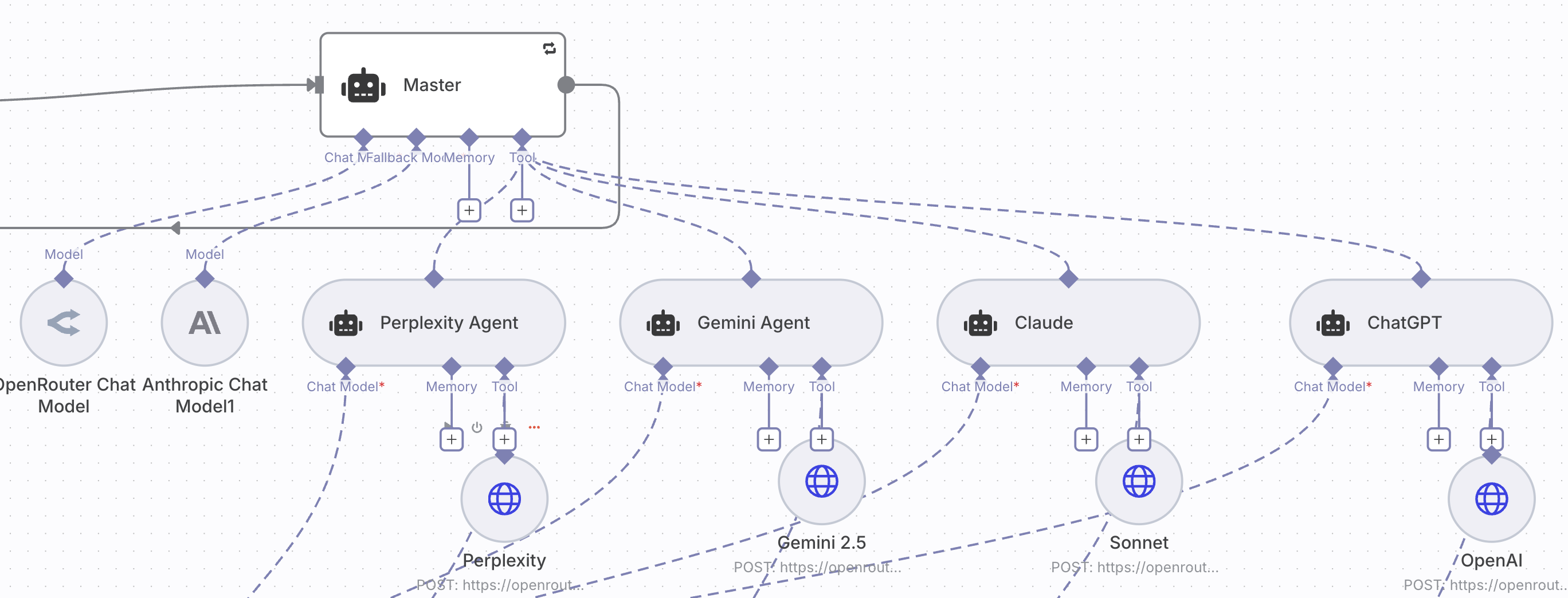
- Parallel Search, Extraction, and Tagging (The Sub-Agents):
- Action: Four Sub-Agents (one for each LLM: Perplexity, Claude, Gemini, and ChatGPT/OpenAI) execute the exact query via their respective APIs, ensuring the LLM's web-grounding/browsing capabilities are enabled.
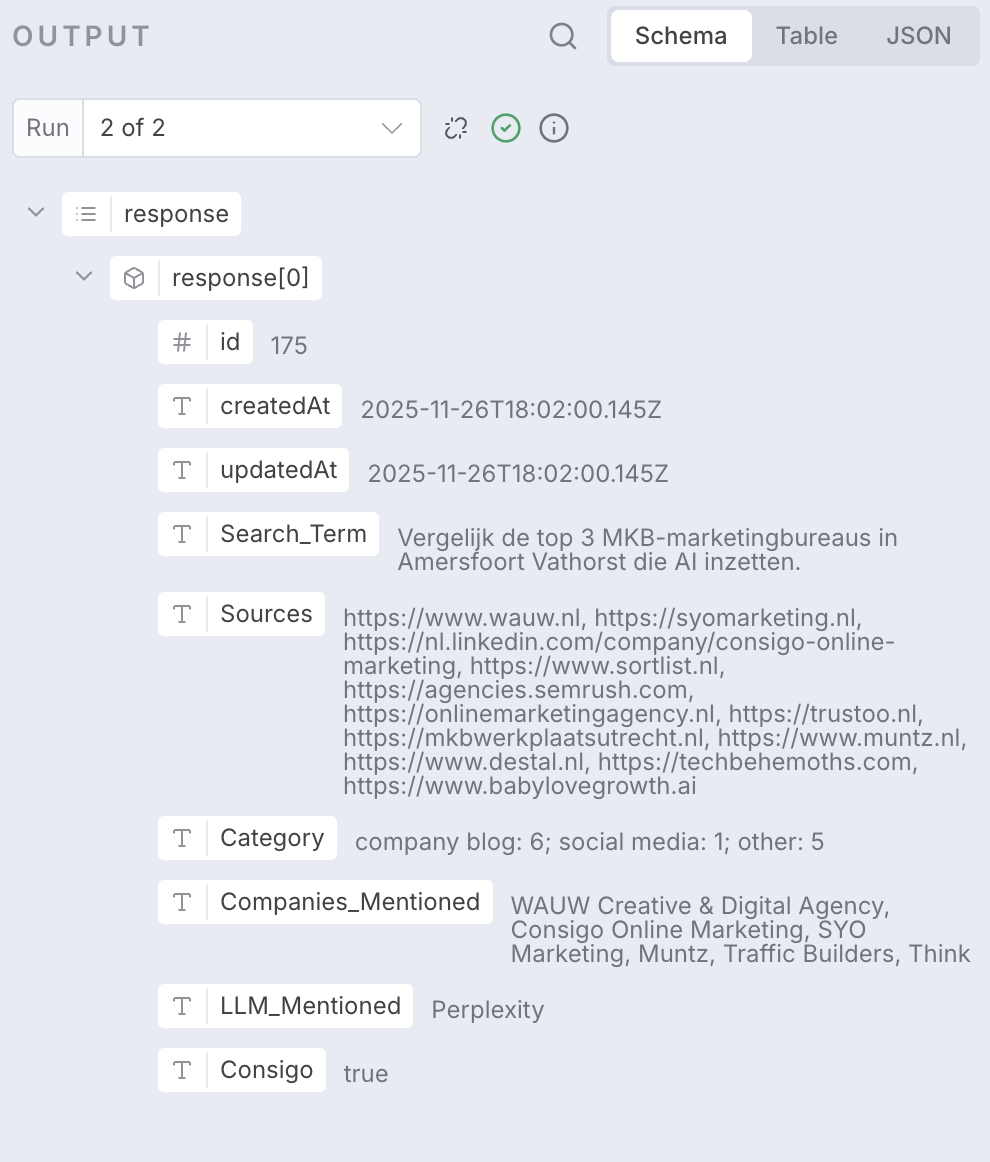
- Extraction: Each Sub-Agent independently performs precise data extraction on its LLM's response:
- Checks for the keyword: "Innovativecompass" (Y/N).
- Extracts all cited sources (URLs/Titles).
- Categorizes source types (e.g., "company blog," "academic paper").
- Lists all unique company mentions.
- Value: Guarantees an unbiased, systematic audit of each model's grounding and eliminates manual extraction errors.
- Data Persistence and Aggregation:
- Action: Each Sub-Agent inserts its individual, granular results into dedicated data tables for an audit trail. The Master Agent then collates the four results, deduplicates all cited sources, and synthesizes the final, unified report.
- Value: Provides both the granular detail needed for technical teams and the high-level, standardized JSON summary required for executive reporting and analytics.
3. The Results: Objective Benchmarking and 95% Efficiency Gain
The implementation of the GEO Prompt Tracker delivered a massive gain in both efficiency and strategic intelligence, allowing the firm to lead with a truly data-driven approach to Generative Engine Optimization.

Key Strategic Outcomes:
- Accelerated GEO Strategy: The firm can now audit hundreds of critical queries in the time it previously took to audit a handful, allowing them to rapidly identify content gaps and areas for optimization to secure AI citations.
- Objective LLM Benchmarking: The standardized output provides clear data on which LLMs use higher-quality sources (e.g., academic vs. forum), enabling clients to select the best model for applications where source authority is paramount.
- Proactive Brand Integrity: Automated tracking of the "Innovativecompass" keyword ensures the firm can instantly identify when its brand or offering is mentioned in AI results, allowing for immediate action if the context is inaccurate or unfavorable.
- Shift to Analysis over Data Entry: By automating data collection and normalization, domain experts are now focused 100% on analyzing the results—identifying LLM-specific content bias, competitive company mentions, and source-type trends—rather than manual data input.
The GEO Prompt Tracker Workflow established a new standard for LLM Auditability and Generative Engine Optimization, transforming a manual chore into a powerful, scalable intelligence engine for the B2B digital landscape.
➡️ Ready to Scale Your GEO Strategy?
Want to move beyond manual testing and gain objective, data-driven insights into how LLMs cite your brand and content? Contact us today to discuss how a custom LLM auditing workflow can accelerate your Generative Engine Optimization strategy.